
本文转载自雷锋的AI掘金
 nu-Net-Net的贡献在于,它不仅可以作为一个现成的分割工具,还可以作为未来医学分割相关发表论文的一个强大的U-Net基线和平台。
nu-Net-Net的贡献在于,它不仅可以作为一个现成的分割工具,还可以作为未来医学分割相关发表论文的一个强大的U-Net基线和平台。
编译|卡卡
最近,德国癌症研究中心、海德堡大学和海德堡大学医院的研究人员发表的一篇名为nnU-Net的医学图像分割论文引起了广泛关注。
该团队提出了一个医学图像分割框架,可以适应任何新的数据集。该框架可以根据给定数据集的属性自动调整所有超级参数,整个过程不需要人工干预。仅依靠简单的U-Net结构和鲁棒的训练方案,nnU-Net在六个公认的分割挑战中取得了最先进的性能。
摘要
在数据集多样性的驱动下,语义分割是医学图像分析中的一个热门子领域,每年都有大量新方法被提出。然而,这种不断增加和复杂的方法越来越难以捉摸。同时,许多提出的方法不能在提出的论文之外推广,这阻碍了在新数据集上开发分割算法的过程。
在这里,我们提出NNU网(“无新网”)3354,一个适应任何给定的新数据集的框架。虽然这个过程到目前为止完全由人类驱动,但我们首先尝试根据给定数据集的属性自动进行必要的调整,比如数据预处理、图像块大小、批量大小、推理设置等。
值得注意的是,nnU-Net去掉了学术界提出的花哨的网络结构,只依靠嵌入在鲁棒训练方案中的简单U-Net结构。NnU-Net在六个公认的细分挑战中取得了最先进的性能。
介绍
语义分割仍然是医学图像计算领域的研究热点,70%的国际比赛都是围绕它展开的。当然,持久关注的重要原因是医学领域遇到的成像数据集的多样性和个体特征:数据集之间的数据尺度、图像维数、图像大小、体素灰度范围和灰度表示都有很大差异。
图像中的类别标签可能高度不平衡或不清楚,并且标签的质量在数据集之间变化很大。此外,一些数据集在图像几何形状上非常不均匀,或者切片之间可能存在未对准和不均匀的间距。总而言之,这些情况使得将一个任务的结果推广到其他任务变得更加困难,当这些方法被重新应用于解决另一个问题时,它们往往会失败。
调整设计决策或提出新的设计概念的过程是复杂的:大多数选择是高度相互依赖的,证明选择的证据分布在无数的论文中,其中包括许多“噪音”。因此,近年来,学者们提出了大量的分割方法。一个突出的例子是:U-Net等带跳跃连接的解码-编码结构的各种变体,包括引入残差连接、密集连接、注意机制、附加辅助丢失层、特征再校准和其他(如自动聚焦层)。
具体的修改各不相同,但它们都特别关注网络结构的修改。考虑到与细分相关的大量论文、具体实现的多样性以及与数据集相关的挑战,越来越难以遵循这些文档来确定哪些设计原则在实验之外真正得到了推广和验证。根据我们自己的经验,许多新的设计概念并没有提高分割性能,有时甚至会损害基线的性能。
当今医学图像计算中的一个关键问题是,将(分割)方法应用于新问题的过程完全由人类驱动。基于经验,本文主要关注网络结构,而忽略所有其他超参数。基线的次优调整通常由新的结构来补偿。由于超参数空间中的强依赖性和大量的局部极小值,使方法适应新的问题是非常困难的,所以在这个循环中没有人能真正受到责备。这种情况让研究者和整个学术圈都很沮丧。尤其是在具有如此多样数据集的医学成像领域,进展很大程度上取决于我们解决这些问题的能力。
本文试图在这个方向上迈出第一步:我们提出了无新网(nnU-Net),一种自动适应新数据集的分割方法。基于数据集的自动分析,nnU-Net自动设计和执行网络训练过程。围绕标准的U-Net网络结构,我们假设给定的一组系统的和精心选择的超参数分割方法仍将产生有竞争力的性能。事实上,在没有任何手动微调的情况下,该方法在几个著名的医学分割基准上实现了最先进的性能。
方法
分割算法可以形式化为函数f (x)=y,其中x是图像,y是相应的预测分割,是训练和应用该方法所需的超参数集。的维数可以很大,包括从预处理到推理的全过程。许多现有的论文通常侧重于报告和确认与最相关的选择。理想情况下,将提供源代码以完全涵盖。但是,如果转换到一个具有不同属性的新数据集,这个过程就缺乏如何调整的深入知识。在这里,我们首次尝试将这一过程形式化。
具体来说,我们寻找函数g(X,Y)=,它在数据集之间是很通用的。第一步,我们需要确定不需要调整的超参数。在我们的例子中,这些超参数反映了一个强大而简单的分割系统和一个健壮的训练方案。这些影响因素是动态的,需要根据X和y变化。
第二步,定义动态参数G,在我们的例子中是一组启发式规则,来调整归一化和重采样方案,配置图像块大小和批量大小,计算网络的具体结构,包括网络集成和推理方法。综上所述,nnU-Net是一个分段框架,可以适应不同的未见过的数据集,无需任何用户交互。
2.1预处理
图像标准化
这一步需要输入数据的模态信息。如果设备不是CT,nnU-Net通过减去平均值并除以标准偏差来标准化强灰度值。如果模态是CT,则根据由训练集分割的前景区域的0.5%到99.5%的灰度分布,自动执行强灰度值的类似窗口级的剪切。为了符合典型的权重初始化方法,使用全局前景均值和标准差来归一化数据。
素数间距
NnU-Net将统计训练数据中的所有音高,并选择每个轴的中值音高作为目标音高。然后通过三阶样条插值对所有训练集进行重采样。各向异性间距(尤其是当面外间距比面内间距大三倍以上时)将导致插值伪影。在这种情况下,我们使用最近邻来完成面外插值。对于每一类分割标签,使用线性插值进行重采样。
2.2培训步骤
网络结构
三个U-net模型(2D U-Net、3D U-Net和两个3D U-Net模型的级联)被独立地配置、设计和训练。在两个3D U-Net模型的级联框架下,第一个模型产生低分辨率分割结果,然后第二个模型执行下一步细化。与原来的U-Net网络相比,我们只做了以下三点改变:一是使用带边缘填充的卷积运算来实现输出和输入形状的一致性,二是使用实例归一化,三是使用Leaky ReLUs代替ReLUs。
网络超参数
这些参数需要根据预处理的训练数据的形状进行调整。具体来说,nnU-Net自动设置每个轴的批量大小、图像块大小和池化次数,使内存消耗保持在特定范围内(12 GB TitanXp GPU)。在该步骤中,较大的H图像块大小优先于批量大小(最小批量大小为2),以获得更多的空间上下文信息。每个轴的大小将小于4个体素。所有U-Net结构在第一层中使用30个卷积滤波器,并且这个数字在每次汇集操作中加倍。在典型情况下,如果所选图像块大小覆盖少于25%的体素,则下采样数据将用于训练级联3D U-Net。级联旨在使nnU-Net在图像块尺寸过小而无法覆盖整个分辨率时,仍能获得足够的上下文。
网络培训
所有U-Net结构都经过了50%的交叉验证培训。每轮设定250个小批量。交叉熵损失和骰子损失之和被用作损失函数。使用Adam作为优化器,初始学习率为3 104,l2权重衰减为3 105。每当训练损失的指数移动平均在最近30个周期没有改善时,学习率下降0.2倍。当学习率低于106或超过1000轮训练时,停止训练。我们在培训期间使用batchgenerators框架进行在线数据增强。具体来说,我们使用弹性变形、随机缩放和随机旋转以及伽马增强。如果数据是各向异性的,则在平面中执行2D空间变换。
2.3推理
使用滑动窗口方法来预测每种情况,其中重叠区域被设置为图像块大小的一半。这增加了中心区域附近的预测权重。通过沿所有轴翻转来执行测试数据增强。
NnU-Net集成是两个U-Net(2D、3D和cascade)的组合,根据交叉验证结果自动选择最佳模型或集成进行测试集预测。此外,nnU-Net还集成了通过交叉验证生成的五个模型。
结果
NnU-Net最初是在医学分部十项全能挑战赛第一阶段的七个训练数据集上开发的。挑战数据集涵盖了医疗细分问题中常见的大量差异和挑战。NnU-Net在医疗十项全能细分挑战(第一和第二阶段)和其他五项流行的医疗细分挑战中接受了评估。所有挑战结果如表1所示。
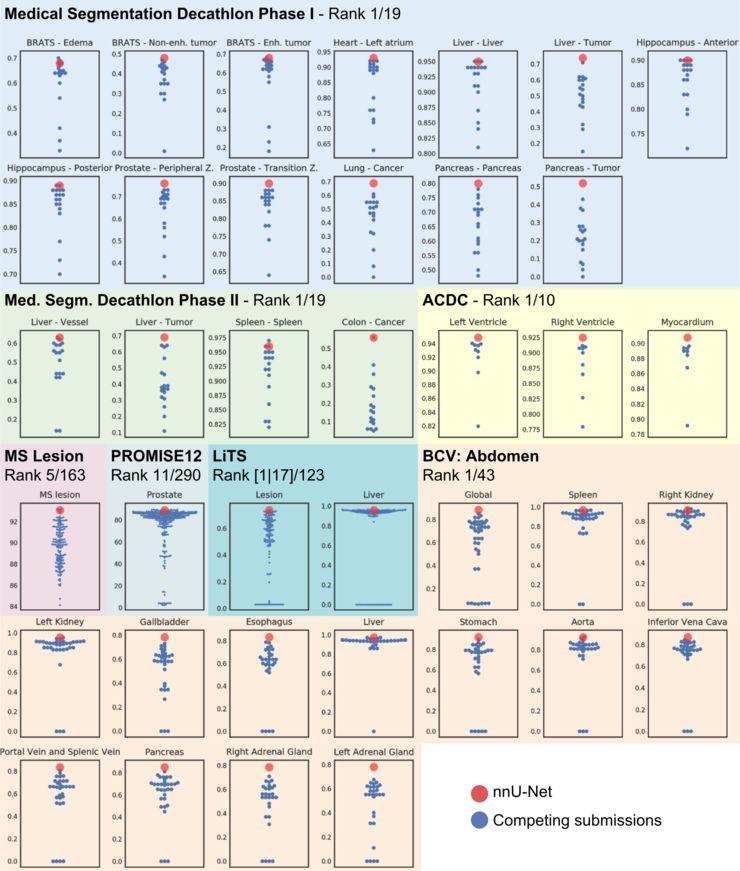 图1显示了nnU-Net在各种医学细分数据测试集中的性能。的所有排行榜提交都在上图中绘制(截至19年3月25日)。迪卡侬、LiTS、ACDC和BCV的值是Dice分数,MS lesion和PROMISE12使用不同的指标。
图1显示了nnU-Net在各种医学细分数据测试集中的性能。的所有排行榜提交都在上图中绘制(截至19年3月25日)。迪卡侬、LiTS、ACDC和BCV的值是Dice分数,MS lesion和PROMISE12使用不同的指标。
医学十项全能(十项全能)
挑战的第一阶段包括上述七个数据集,参与者使用这些数据集开发可扩展的分割算法。在第二阶段,提供另外三个先前未知的数据集。该算法应用于这些数据集,无需进一步的更改或用户交互。两个阶段的评估都是在官方测试集上完成的。在第一、第二阶段,nnU-Net在十项全能挑战中优势明显。
心脏分割挑战(ACDC)
每个心脏的电影MRI图像的两个阶段被分成三个部分。挑战赛提供100个训练案例,每个案例有两个课时。我们手动分割nnU-Nets的数据以进行50%的交叉验证。NnU-Net获得了公开排名(基于50个测试用例)的第一名,在这个数据集上达到了最先进的水平。
纵向多发性硬化病变的分割挑战
任务是分割磁共振图像中的多发性硬化症。提供5个患者,每个患者有4-5个时间点(共21个时间点),有两个评价者,在每个时间点提供评论。我们将每个评估者视为一个独立的训练集,并手动分割训练案例以确保患者分层。在测试集中,nnU-Net在163篇投稿中排名第5,得分为93.09,仅落后于范德堡大学的4篇投稿,最高得分为93.21。
承诺12
任务是分割各向异性MRI图像中的前列腺。有50个标记的训练案例和30个未标记的测试案例。NnU-Net在测试集中的得分为89.08,在总共290份提交材料中排名第11位(第一名:89.59)。
隶
肝脏分割的挑战包括131个训练图像(CT)和70个测试案例。对于训练病例,提供了肝脏和肝肿瘤的分割。nnU-Net在病灶和肝脏中的Dice值分别为0.725和0.958。通过去除除了用于后处理的最大连接前景区域之外的所有区域,骰子分数增加到0.738和0.960。公开排名中病灶分割的Dice评分达到最先进水平,肝脏分割在123支队伍中排名第17(第一名:0.966)。
超越颅穹窿挑战(腹部)
该数据集的任务是分割腹部CT图像中的13个器官。该挑战提供了30个标记的训练图像和20个测试图像。NnU-Net在这个数据集上达到了最先进的水平,平均骰子得分88.1%,比第二名高出3分(排行榜有43篇投稿)。具体来说,nnU-Net在13个器官中的11个器官中得分最高。
表2显示了旨在验证nnU-Net选择的消融研究。所有实验都是在迪卡侬第一阶段的代表性数据集上进行的,使用相同的数据划分。一方面,这些结果表明我们应该修改泄漏ReLUs的使用,另一方面,它们验证了我们选择的实例规范化、数据增强和损失函数的效果。
 如图2所示。通过nnU-Net设计选择消融实验。利用部分训练数据和3D U-Net,在迪卡侬的代表性数据集上进行了实验。nnU-Net的值表示平均前景Dice分数(例如,肝脏数据集的肝脏和肿瘤筛选系数的平均值),消融研究的值表示Dice分数的百分比变化。
如图2所示。通过nnU-Net设计选择消融实验。利用部分训练数据和3D U-Net,在迪卡侬的代表性数据集上进行了实验。nnU-Net的值表示平均前景Dice分数(例如,肝脏数据集的肝脏和肿瘤筛选系数的平均值),消融研究的值表示Dice分数的百分比变化。
讨论
我们引入了nnU-Net,这是一个无需用户干预就能自动适应任何给定数据集的医学分割框架。据我们所知,nnU-Net是第一个试图形式化数据集之间必要调整的分割框架。NnU-Net在六项公开分段挑战中取得了最先进的性能。这是非常了不起的,因为nnU-Net并不依赖于近年来提出的各种复杂的划分结构,而仅仅依赖于简单的U-Net结构。必须强调的是,我们没有手动调整挑战数据集之间的超参数,所有的设计选择都是由nnU-Net自动确定的。更令人惊讶的是,它在一些数据集上的表现优于其他专门人工设计的算法。
NnU-Net包括一些通用的固定设计选择,如U-Net结构、骰子损失、数据增强和模型集成,以及一些由遵循我们的细分经验的一组规则确定的动态设计选择。虽然,用这样的规则可能不是解决这个问题的最好办法。给定更多的数据集,以后的工作可能会尝试直接从数据集的属性中学习这些规则。虽然选择nnU-Net可以在多个数据集上取得很强的分割性能,但这并不意味着我们找到了全局最优配置。
事实上,从表2所示的烧蚀实验可以看出,选择泄漏ReLU而不是ReLU并不影响性能。我们的数据增强方案可能不适合所有数据集,后期处理需要进一步研究。我们在LiTS的结果表明,正确的后处理可能是有益的。这种后处理可以通过分析训练数据或者通过选择基于交叉验证结果的方案来自动化。这种自动化的尝试是十项全能挑战期间nnU-Net初始版本的一部分,但后来因为无法持续改善成绩而被放弃。
现在我们已经建立了迄今为止最强大的U-Net基线,我们可以系统地评估更高级网络设计的通用性以及与这里采用的通用架构相比的性能改进。因此,nnU-Net不仅可以作为一个现成的分割工具,还可以作为未来医学分割相关论文的一个强大的U-Net基线和平台。
![]() 原https://arxiv.org/abs/1904.08128
原https://arxiv.org/abs/1904.08128
开放源地址https://github.com/MIC-DKFZ/nnunet


