
摘要:
随着深度学习的发展,图像语义分割的任务有了很大的突破。然而,视频语义分割仍然是一项非常具有挑战性的任务。本文将介绍近年来在视频语义分割方面的一些工作。
1.基本任务介绍:
语义分割任务要求图像中的每个像素都被赋予一个语义标签,而视频语义分割任务要求每帧视频中的每个像素都被赋予一个语义标签。
近年来,随着卷积神经网络的发展,特别是全卷积网络的出现,语义分割的任务在各种数据集上都取得了很大的突破。这个任务本身有很多应用场景,强调的是计算机对场景的感知和理解,所以在机器人视觉、自动驾驶等应用中占有重要地位。但实际上,相对于单个图像,我们更容易获取视频数据,而视频数据本身具有很强的帧冗余性和不确定性。如果我们直接把视频一帧一帧的送入图像分割模型,必然会带来大量的计算开销,而且由于场景中运动物体的变化,分割结果会不稳定,比如一个物体的前一帧是A类,但是在几帧中间突然变成了B类,或者物体内部出现了语义类。所以目前视频语义分割的主要研究重点大致是两个方向:第一个是如何利用视频帧之间的时序信息来提高图像分割的准确性,第二个是如何利用帧之间的相似性来降低模型的计算量,提高模型的运行速度和吞吐量。
任务的评价指标是Miou(Mean Intersection-Over-Union),与图像的语义分割相同。因为是视频数据,所以模型的FPS会作为视频加速方向的一个平衡来测试。目前主流的数据集Cityscape,Cityscape,这是目前主流的基于自动驾驶场景的语义细分数据集。此外,有些文章还使用了Camvid数据集。
2.方法介绍
2.1图像语义分割概述
在这里,我将简单回顾几个经典的图像语义分割模型。目前最先进的模型大多采用特征网络(主干)加跟随模块(上下文建模)。其中特征网络一般是深度分类网络,比如resnet系列。这一部分的主要目标是获得更好的特征表示。上下文模块的目标是建立每个像素的特征之间的关系,进而获取整幅图像的场景信息,使分割结果的语义一致性更强,这也是目前的研究热点。
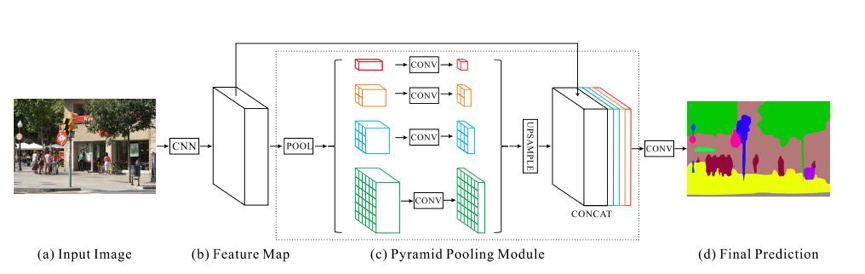 图1: PSP网
图1: PSP网
PSP-net以resnet101作为网络主干,提出使用金字塔池模块,即特征网络的金字塔结构作为上下文建模,获取不同尺度的信息。具体来说,resnet最后一个块的输出经过四个不同尺度的平均池操作,然后采样回原始尺度,最后融合这些不同尺度的信息,从而更好地捕捉不同尺度的上下文信息。
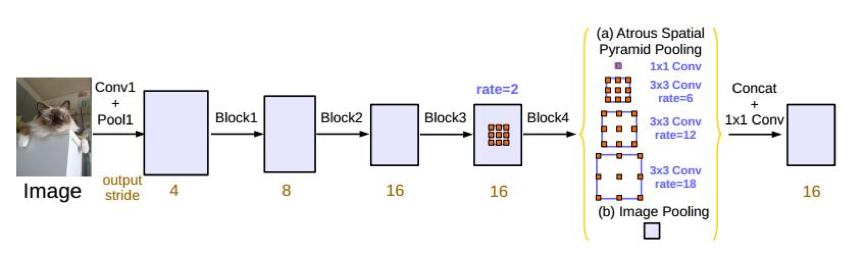 图2: ASPP模块
图2: ASPP模块
Deeplabv3也以resnet101为网络主干,提出了ASPP的结构,通过不同膨胀率的卷积运算获得不同尺度上下文的信息,并通过融合全局上下文(图中图像池)进一步提高特征表示能力。
视频语义分割的许多基本模型都是基于图像的语义分割模型,其工作的重点是如何有效地对时间维度的信息进行建模。
2.2利用计时信息提高准确度方向:
该方向的主要工作是利用视频的时序信息,获取语义信息一致性更强的特征进行分割。
2.2.1通过表示扭曲的语义视频CNN(ICCV,2017年)
图3:网络架构
本文提出了一种称为Netwarp的结构。其主要作用是利用光流将前一帧的特征移动到当前帧,从而在一定程度上增强特征。光流被定义为两幅图像之间对应像素移动的矢量,这种结构可以插入视频的帧之间(如图3所示)。
图4:网络扭曲模块
该模块的具体操作如图4所示。模型的输入是两个连续的帧,其中(t-1)代表前一帧,t代表当前帧。第一步是计算两帧之间的光流F(t)。这里的光流计算是离线的形式,即预先计算好每个光流,具体的光流计算方法是Dis-Flow。然后,光流和两帧图像被送到一个叫做Transform Flow的模块,这个模块由一个小的全卷积网络模块组成。它的设计目的是用图像信息补充光流信息(如下图5所示,可以看出transflow除了运动信息之外,还包含了物体的详细信息)。之后利用transform的flow将前一帧的特征扭曲到当前帧(warp的具体实现是利用双线性差分运算,就是根据当前帧的特征点从光流信息中找到前一帧对应的特征点,然后将特征点带过来,后面介绍的很多作业都会用到这个运算)。最后,结合当前帧和前一帧的信息,得到最终的特征表示。最终的实验结果可以提高基于PSP网络的网络性能。
 图5:分流和转换流
图5:分流和转换流
2.2.2通过门控循环流传播进行语义视频分割
上一篇文章主要是结合两帧之间的特征信息。这项工作是结合多个帧的未标记信息,以提高分割性能。本文提出了一个名为时空转换器GRU的模块,如下图6所示。与以往操作特征的工作不同,这里作者只对分割结果进行操作,通过组合不同时间维度的结果来指导图像分割网络的学习。
图6: GRFP结构
图6中的时空变换器gru (stgru)本质上通过光流信息将前后标签图与当前帧t相结合。考虑到前一帧的一些信息对当前帧的分割没有帮助,比如前几帧没有出现的一些汽车零件,就是用光流移动到当前帧的,这些信息对当前帧的分割没有帮助。所以作者用gate的思路,让网络学会组合不同的语义图。在这里,他使用卷积GRU融合不同时间点的信息。卷积GRU的具体操作是利用卷积来学习相邻帧的局部信息,因此可以更好地融合不同位置的语义表示。这里光流生成网络采用的是flownet2,这是一种在线计算光流的方式,使得整个框架工作可以端到端的训练和学习。
STGPU的具体计算过程是:首先计算相邻两帧的光流和两个不同语义的分割结果图,然后通过光流将前一帧的结果扭曲到当前时间,再将扭曲结果和当前帧的分割信息发送到GRU的模块,得到一个输出作为当前帧的分割结果。如图,前一帧的路灯(灰色)经过STGRU后将信息传递给当前帧,弥补了当前帧的分割不准确。
图7: STGRU培训框架
整个框架就是将STGRU插入到图像语义分割网络中。对于当前帧,它会考虑将前后帧作为输入,从每个样本帧的前后计算样本帧和当前帧(cityscapes上的第20帧)的光流。并通过卷积GRU将多帧的语义分割图从前到后、从后到前传输到当前帧(此时会有两个STGRU模块,图7中的gf和gb),最终得到一个具有双向时态信息的特征表示,然后计算损耗进行反向传播。在训练时,作者会先训练图像的语义分割网络,然后固定Flownet的参数,再去微调STGRU和语义分割网络。笔者在这里尝试了几种不同的分割网络,包括PSP、Dilation10等。它们的性能都得到了一定程度的提升。从某种意义上说,这个框架就是学习如何更好地融合多帧时间序列信息。
以上工作均使用未标记的视频数据,且均使用光流信息融合特征或语义图,以获得更好的特征表示。
2.3减少视频冗余的计算方向:
由于视频中帧与帧之间的相似度很高,如果将图像逐个送入神经网络,必然会带来大量的冗余计算。在一些特定的应用中,比如自动驾驶任务,模型的运行速度也是一个重要的因素,所以近年来,人们做了大量的工作来研究视频分割加速。
2.3.1视频识别的深度特征流(CVPR 2017)
深度特征流是近年来视频任务的代表作之一。本文的出发点是,视频中深度特征的帧间差异相对较小,但对于每一帧,获取深度特征的时间和计算成本都是极大的(尤其是对于一些深度网络)。作者考虑使用光流将之前的特征扭曲到当前帧,从而减少计算量。
图8: DFF框架
如上图所示,会先选择一帧,表示当前帧可以通过全网获得深度特征。对于不是关键帧的帧,会计算它和关键帧之间的光流(这里是通过flownet-s),然后深度特征warp把关键帧通过光流扭曲到当前帧,得到当前帧的分割结果,然后得到损失。在这里,关键帧的选择是固定的,并且每k个关键帧被选择。由于光流网络是浅层的,计算量远小于分割网络,因此可以大大提高分割速度。DFF还可以处理其他视频任务,如视频对象检测,因为这种操作是在特征传播的级别上进行的,与下面的特定任务无关。
DFF是加速视频语义分割的开创性工作,后来的很多工作都是基于这个框架。
2.3.2低延迟视频语义分割(CVPR 2018)
DFF的关键帧选择是固定的,那么如何更自适应地选择关键帧呢?本文给出的答案是低级功能。本文的出发点是低层特征的变化在一定程度上代表了是否选择一个关键帧,因为如果帧的内容变化很大,底层特征的差异,比如边缘位置信息也会很大。为此,作者还做了一个实验来分析。笔者在Cityscape和Camvid上观察到,底层特征差异越大,框架内容差异越大。第二个创新点是在使用warp深度特征时,通过卷积而不是光流将之前的深度特征移动到当前帧,同时对当前帧的整帧进行合成,如下图所示:
低延迟框架结构
S(l)代表网络提取低层特征,S(h)代表获得深层特征。在实施中,它可以被认为是同一网络的两个不同阶段。对于每个新的输入帧,低层特征将通过S(l)获得。然后将当前帧和前一关键帧的底层特征送入一个小的FCN网络中预测一个值(文中称为权重预测器,如下图)。该值表示当前帧是否是关键帧的可能性。如果超过一个阈值,它将输出1,表明当前帧的内容与上一帧的内容有很大不同。否则,它将输出0,这意味着它不是关键帧。这个小FCN可以自适应地学习每一帧作为一个关键。
图10:特征传播的模式
对于关键帧,底层特征会像DFF一样继续通过S(h)得到深层特征。对于非关键帧,作者使用另一个小FCN(图10中的权重预测器)来预测权重。这个权重W是一个K*K*w*h的张量,也就是说从关键帧上的每一点到当前帧都有一个K*K的卷积核,然后通过卷积把之前的深度特征传递给wrap。从图10中,我们可以看到,权重预测器可以使深度语义特征变得非常好。最后,融合当前帧的低层特征和变形后的深层特征作为当前帧的输出。
\(f_{h}^{t}(l,i,j)=\sum_{u}\sum_{v}w_{ij}^{(k,t)}(u,v)f_{h}^{k}(l,i-u,j-u)\)
与DFF相比,本文考虑了低层特征,显著改善了分割结果,并提出了一种低延迟调度策略来进一步提高速度。这个策略就是在计算关键帧的特征时,可以用一个过程,用特征翘曲的方式计算出一个假货的深度特征。另一个过程还是计算关键帧的深度特征,然后非关键帧用这个假货的深度特征计算。但是真实的过程会在计算之后替换掉这个fake的深度特征,让接下来的非关键帧使用这个真实的深度特征来得到输出结果。这种策略以牺牲一定的准确性为代价来提高速度。
摘要
简要介绍了两种具有代表性的视频语义分割方法,认为未来的研究方向将逐渐从图像转向视频领域。
参考资料:
(1)通过表示变形的语义视频CNN。在2017年的ICCV
(2)克鲁格、戴和古尔使用密集反向搜索的快速光流。2016年欧洲计算机视觉会议。
(3)基于门控循环流传播的语义视频分割。在2018年的CVPR
(4)伊尔格、迈耶、塞基亚、凯乌珀、多索夫茨基和。布罗克斯。深度网络光流估计的发展。2017年在CVPR。
(5)低延迟视频语义分割。在2018年的CVPR
(6)视频识别的深度特征流(CVPR 2017)
