
语义分割要求图像中的每个像素都被赋予一个语义标记。语义视频分割要求给每个视频帧中的每个像素一个语义标签。
视频分割是一种广泛使用的技术,可用于分离场景的前景和背景。通过修改或替换背景,可以在现实中不存在或难以实现的场景中设定任务,可以增强信息的影响力。传统上,视频图像的逐帧遮罩可以手动完成(在专业的工作室环境中拍摄,屏幕为绿色,去除背景,切换到图1的后期效果)。比如复仇者联盟,美国队长,钢铁侠等专业软件(比如Pr,幻影)可以用来添加各种逼真的特效。让电影更有趣,更震撼。可想而知,2019年北京卫视和浙江卫视都会有这样的特效,不用手动一帧一帧的映射一个姓吴的有名大叔,也是如此和谐。

特效和绿屏消光
本文首先总结了视频分割的基础,如视频对象分割的分类、评价指标、数据集等,详细介绍了Google为YouTubeapp设计的移动视频分割方法,以及CVPR2019在视频领域的最新进展。段,简单介绍一下RVOS,重点是准确性和实时性。平衡的感觉和暹罗面具。
1.视频分割的基础
1.视频对象分割和分类
语义分割分为图像语义分割和视频语义分割,如图。
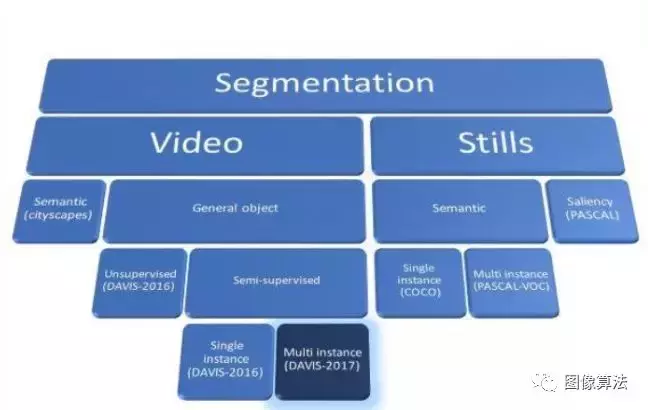
语义划分领域划分
经典的基于图像的语义分割算法包括FCN、SegNet、扩展卷积、DeepLab(v1 & amp;v2 & ampv3)、RefineNet、PSPNet、大内核等等。然而,视频对象分割和图像语义分割有两个基本区别。视频对象分割的任务是分割非语义对象,而视频对象分割增加了一个计时模块,它的任务是在视频的每一个连续帧中找到目标对应的像素。使用经典的语义分割算法很难直接实现视频处理的性能,这也是基于时间序列的MaskTrack算法优于基于视频独立帧处理的OSVOS算法的原因。
2.视频分割的评价指标
视频目标分割的评价指标包括轮廓精度、区域相似性和时间稳定性。
区域相似度:区域相似度是掩膜M和真实g的联合函数。
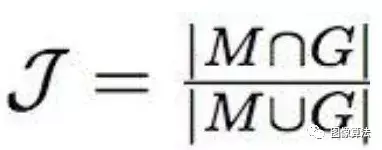
轮廓:将掩膜视为一组封闭的轮廓,由轮廓计算F度量,即精度和召回率的函数。也就是说,轮廓精度是基于轮廓的精度和召回率的F度量。
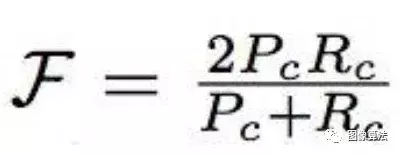
直观上,区域相似度衡量的是错误标记像素的数量,而轮廓精度衡量的是分割边界的精度。
3.视频分段数据集
视频分割领域的数据集包括戴维斯系列(DAVIS-2016,DAVIS-2017,DAVIS-2018),youtube-VOS,GyGO:Visualead的电子商务视频对象分割,基蒂MOTS(多目标跟踪和分割)和MOTS挑战数据集。
2.谷歌:移动视频分割
1.移动终端和视频分割
视频分割可以在移动终端上实现,比如华为Mate 20系列新推出的人像保色功能(人像保色或者人像分割是视频分割的一部分,分割目标是人体),可以在视频录制过程中实时识别轮廓为人的人物,然后通过AI对其颜色进行优化。周围的景物都是黑白的,这样才能让主角突出,营造出大的视觉体验。

肖像着色
如图,衣服的颜色、肤色、头发都留在了图像的主体里。相反,背景中的地面、栏杆、台阶和远处的树木都变成了黑白的。总的来说有大电影的视觉感觉。
本节主要介绍Google针对手机摄像头的实时视频分割消光技术。本文中视频分割的效果是惊人的。可以在iPhone 7上运行100 FPS。

视频分割
它是故事YouTube的一种轻量级视频格式。将视频分段与故事结合起来,可以为YouTube应用提供准确、实时、便携的移动视频分段体验(需要有换墙的体验)。
谷歌提供的视频分割技术不需要专业设备,创作者可以轻松替换和修改背景,从而提高视频制作水平。为了解决基于移动神经网络的语义分割,满足以下条件:
移动解决方案必须是轻量级的,达到每秒30帧才能实现实时推理。
l视频模型需要利用时间冗余(相邻帧看起来相似)和时间一致性(相邻帧得到相似的结果)。
高质量的分割结果需要高质量的标签。
2.标记数据集
为了获得高质量的数据集,Google标记了10W张图片,包括丰富的前景和背景信息。前景标注实现了精细的像素级定位,如头发、眼睛、脖子、皮肤、嘴唇等。实现了98%以上的IoU人工标注质量。目前谷歌还没有公布这部分数据集(图5)。它可以使用另一个开源数据集,主管人数据集[2],而不是训练模型。

标记谷歌肖像数据集
3.网络体系结构

网络架构输入通道
根据模型参考文献[3],网络模型的输入帧是当前帧(t)RGB三个通道加上前一帧(t-1帧)的二值掩码。前一个遮罩是前一帧的结果。如果是视频的第一帧,前面的掩码可以是全零的矩阵。
模型训练中的第一个视频帧没有遮罩,因此需要一种算法来将地面真实遮罩转换为可能的先前遮罩。使用谷歌[3]方法:
使用空的前一个遮罩直接模拟视频的第一帧。
l在模拟蒙版上进行仿射变换,模拟人对镜头的移动/上/下/前/后。
l薄板样条用于地面上的真实遮罩。谷歌表示,它可以模拟摄像头的快速移动和旋转。
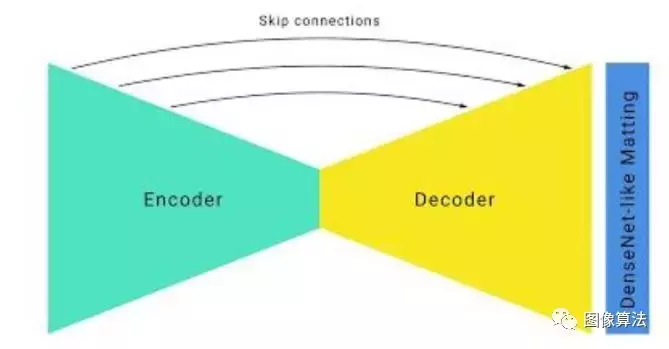
Unet沙漏网络架构
Google在移动端使用Unet沙漏架构。沙漏是人体姿态估计的常用框架。模型推理的速度很慢。谷歌已经做了一些改进。
RGB特征提取采用大卷积核,stride=4以上,计算复杂度较小。
利用大范围下采样和Unet跳转连接,可以加快上采样中低层特征的恢复。
修改ResNet瓶颈。ResNet瓶颈实现了四通道压缩(256通道压缩到64通道),而Google压缩到16通道,没有明显降低功能质量。
为了提高垂直边缘的精度,在网络末端增加了几层DenseNet层(使用了深度图像抠图中的一些思路)。
这些改进在移动设备上实现,iPhone 7上100 FPS,Pixel 2上40 FPS,谷歌自己的标记数据集上94.8%的准确率,以及YouTube故事的流畅运行。
由于Google公布的技术只是博客[1],没有公布训练细节和详细的网络架构,很难复制。
4.优势和劣势分析
谷歌的移动视频分割可以在普通设备上运行特效。IPhone 7似乎也不是低端手机。华为在Mote 20中实现了人像彩色,人工智能进入了人类生活的方方面面。
Google提出了很多参考方向,比如使用ResNet瓶颈的模型压缩,大体积核,大步长等。对于数据集,可以使用通常用于视频分割的Lucid Dreaming(实际上,ground truth是一种在图像上进行辐射变换和随机放置,以及数据增强的方式)。
谷歌没有开源数据集和模型细节,这使得模型的重现更加困难。
3.费尔沃斯
Feevos [5]是德国亚琛工业大学和Google联合提出的视频分割算法。主要解决半监督视频分割中推理速度慢、网络结构复杂的问题。神经网络依靠第一帧的微调,实现基于嵌入向量机制、全局匹配和局部匹配的多目标分割。简单、快速推理、端到端实现和高鲁棒性。f占DAVIS 2017验证集的65%,在视频分割的速度和精度上取得了平衡。
1.运动
DAVIS视频对象分割挑战是CVPR会议的研讨会之一。监督半视频对象分割的任务验证偏向J & ampf指数,且对模型的实时性要求较低。比如2018年戴维斯挑战赛冠军模型PReMVOS,集成了四种不同的神经网络,每帧视频推理时间为38。其次,不能满足实时性的要求。本文设计了一个简单(单个神经网络)、快速推理(无需微调第一帧)、端到端实现和多目标分割的应用。首先是鲁棒性高的戴维斯2017。
基于逐像素度量学习(PML),提出了一种学习嵌入向量和邻域匹配(包括全局匹配和局部匹配)作为神经网络特征的方法。结合骨干特征,前一帧的预测掩码有4个维度,用于端到端的模型训练。
2.网络体系结构
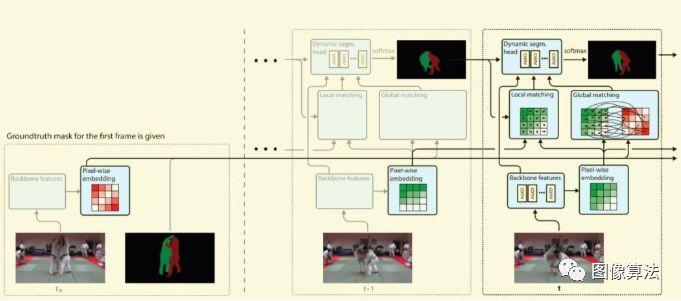
FEELVOS模型架构
如图8所示,FEELVOS神经网络的架构包括主干特征、像素嵌入、局部匹配、全局匹配等动态分割头。
在视频处理过程中,通过主干和嵌入层提取视频中每一帧的每个对象,提取嵌入特征。根据嵌入向量,计算当前帧和前一帧之间的局部匹配距离图,并计算当前帧和视频的第一帧之间的全局匹配距离图。动态分割头堆叠了四个特征(主干特征、局部匹配距离图、全局匹配距离图和前一帧掩模预测),并使用深度可分离卷积和软最大值来预测当前帧的掩模信息。
上述计算过程适用于每个对象。随着对象的增加,计算时间线性增加。
主干为Deeplabv3 (Xcept-65,比原RGB图像降低了4倍的特征分辨率),嵌入层输出嵌入向量。主干提取功能是一种共享方法,它可以为每个图像计算一次特征。每个嵌入向量对应于步幅=4的RGB图像区域。不同帧图像或同一幅图像的两个像素属于同一类,它们的嵌入向量非常接近。如果两个像素属于不同的类别,那么它们的嵌入向量就很远。
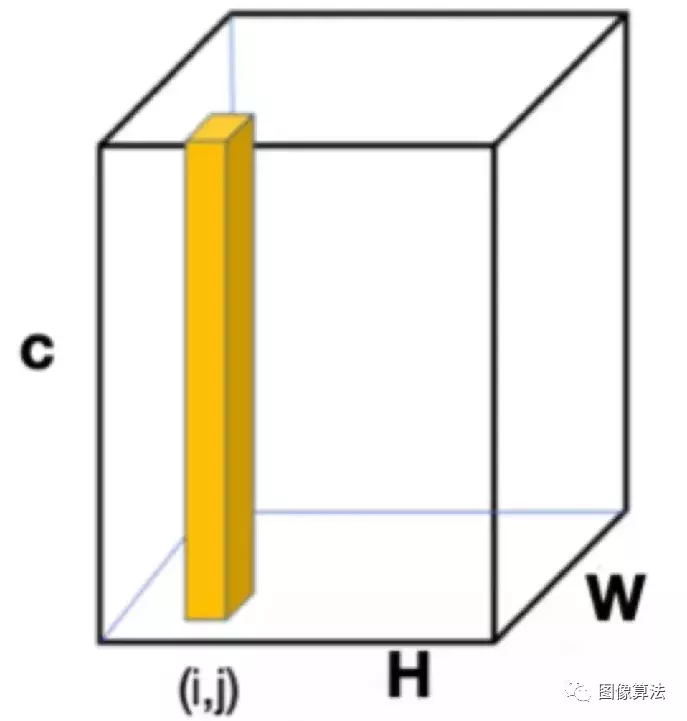
嵌入特征图p,q表示两个像素,ep和eq分别表示对应的嵌入向量,表示嵌入空间距离。计算方法如下:
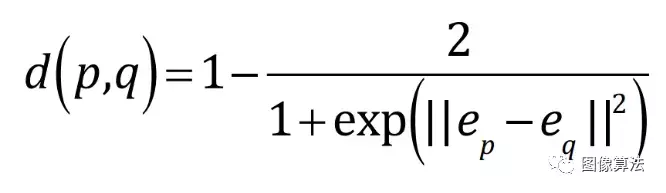
D(p,q)的取值范围是[0,1]。对于同一类像素,我们很容易发现d的值应该非常接近0或者0;对于不同类型的像素,d接近1或1。
嵌入层由深度可分离卷积、33卷积层和11卷积层组成。提取的特征尺寸是100。在逐像素嵌入的基础上,计算当前帧和第一帧视频之间的全局匹配距离图。计算当前帧和前一帧之间的局部匹配距离映射。
计算全局匹配距离图是耗时的。本文输入图像的像素为465 x 465,嵌入层的输出为(465/4)x(465/4)x 100。每一帧都需要用第一帧计算距离图,非常耗时。
可以简化局部匹配距离图的计算。目标在前一帧和当前帧中的运动通常很小。不必使用当前嵌入特征的向量来仅计算k个邻域大小中的第一帧的所有嵌入向量的距离。
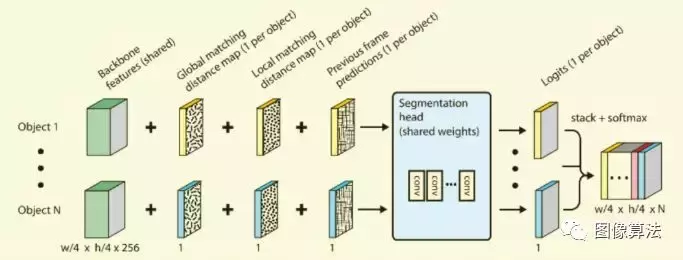
动态分段头网络结构
动态分段头网络输入分为四类:主干特征、全局匹配距离图、局部匹配距离图和前一帧的掩码输出。
动态分割头由四个深度分离的卷积(7×7卷积核)组成,生成一维特征图(1 xw/4 xh/4)用于预测类别。对于每一个目标,都需要动态划分表头来计算逻辑。
本文的实验环境是烧蚀研究。动态分裂头网络有四个输入。作者禁用了一些输入,做了6个实验。结果表明,局部匹配和全局匹配非常重要,丢弃它们会导致网络性能显著下降。
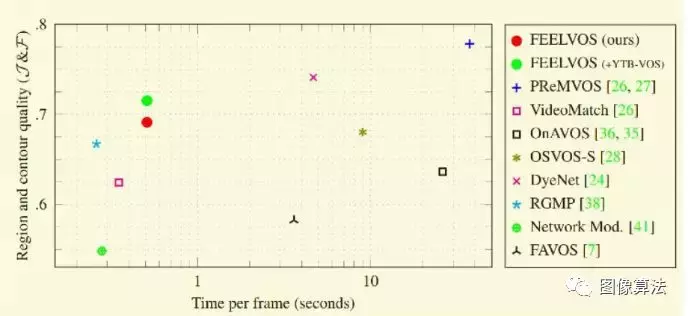
DAVIS2017中FEELVOS的耗时比较
3.分析优势
2.在全局匹配阶段,需要当前帧和第一帧的特征映射来计算所有匹配关系。这篇论文已经简化到样本第一帧每个物体1024像素,计算量还是很大的。
3.不需要计算第一帧和每一帧的全局匹配。例如,对于慢动作视频,跳过5或10帧。只有局部匹配计算会带来累积误差,全局匹配可以修正累积误差。
4.当计算当前帧的掩模时,它依赖于前一帧的掩模。随着视频序列的增加,掩模误差会累积增加。建议添加掩模来监控对准过程。
这个模型对第一帧的基本事实影响较大。例如,在本文提供的实验中,第一帧是一只猫的分割图像,后面区域没有标记。在随后的预测中,对猫背部区域的预测不是很好。
4.RVOS
视频目标分割依赖于时间相关性和空间相关性,LSTM在处理时间序列方面具有天然优势。在ConvLSTM的基础上,加泰罗尼亚开放大学的学者提出了基于RNN的视频分割算法ROVS,解决了单镜头和零镜头多目标视频分割问题,在P100上实现了44 ms/帧的推理处理速度。图形处理器.
1.ConvLSTM
LSTM在语音识别、视频分析和序列建模方面取得了长足的进步。传统的LSTM网络由五个模块组成:输入门、遗忘门、单元、输出门和隐藏。
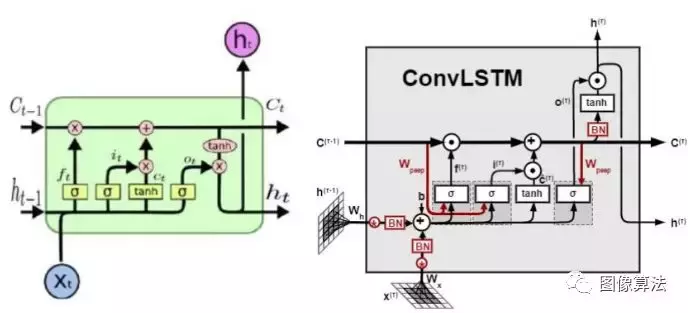
LSTM和康维尔斯特姆足球俱乐部
LSTM结构也可以称为FC-LSTM,因为它的内部部门是依靠一个类似前馈的神经网络来计算的,这种网络处理时间序列数据很好,但对于空间数据。在这种情况下,会出现冗余,因为空间数据具有很强的局部特征,而FC-LSTM无法描述局部特征。ConvLSTM试图通过用卷积形式的前馈计算代替FC-LSTM的输入到状态和状态到状态部分来解决这个问题。
2.网络体系结构
如RVOS网络架构图13所示,骨干网是典型的编码器,每帧n个目标对应n个rnn。本文提出的模型解决了两个问题:一次点击和零点击VOS。
单镜头VOS是一个普通的DAVIS任务,它根据初始化帧和图像序列的掩膜来预测视频序列的掩膜。对于零拍摄VOS任务,输入仅仅是RGB图像。
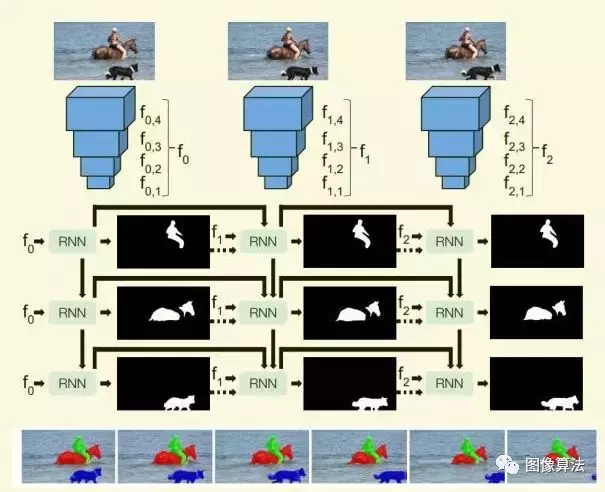
RVOS网络架构
零拍VOS在没有任何先验知识的情况下将目标从视频序列中分离出来,模型必须检测并分割出视频中出现的目标。YouTube VOS和戴维斯是为单镜头VOS设计的。视频序列中没有注释信息的未初始化对象对于零镜头VOS是非常困难的。本文在每幅图像中划分10个目标,预计预测5个目标。
3.优势和劣势分析
1.多目标实体分割的性能取决于被分割实体的数量。
第二步。虽然RNN在处理时间上有明显的优势,convlstm也可以用来处理图像,但是它对存储空间的依赖性很强,很难达到实时的要求。
我个人认为,零拍VOS已经脱离了VOS分类,视频可以分解成序列图形,每个图像都可以在图像中进行物理分割和匹配。
5.连体面具
摩托化
跟踪和视频对象分割(VOS)虽然属于视频分析领域,但并没有犯水刑。视觉目标跟踪的任务是在给定目标在视频序列初始帧中的大小和位置的情况下,预测目标在后续帧(通常以帧的形式)中的大小和位置。早期的跟踪算法采用了轴对齐的矩形框。VOT2015旋转矩形框后,跟踪精度要求提高,实时掩膜为近视计算。
VOS是根据初始帧的掩码预测视频序列的掩码。在VOS领域,一般基于光流法,离线训练,需要对初始帧的掩膜真值进行微调,降低了视频分割的实时性,限制了视频分割的应用范围。
Siammask[8]由中国科学院自动化研究所和牛津大学合作设计,结合视频目标跟踪和视频分割,实现实时像素级目标定位。初始化简单,初始帧中只给出目标的包围盒,在后续的图像序列中计算估计的包围盒和目标分割掩膜。
2.网络体系结构
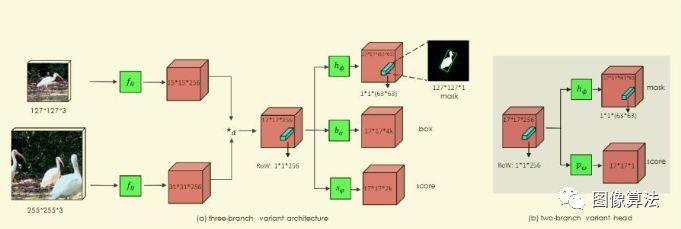
暹罗网络体系结构
Siammash网络架构如图2所示。14是基于暹罗网的追踪器。进一步引入掩模分支以获得分割结果和跟踪目标信息。这一步其实在一定程度上相当于解决了目标尺度变化的问题。
127x127x3是0帧的模板补丁。255x255x3是搜索区域,来自第n帧的局部区域。两个分支共用一个主干,分别得到15 * 15 * 256和31 * 31 * 256的特征图。然后通过深度卷积得到17 * 17 * 256的特征图。
掩码分支是暹罗网的新成员,它使用向量对行掩码进行编码。这使得每个预测位置具有非常高的输出大小(63 * 63)。本文采用深度卷积级联1×1卷积实现高效运算。
图14中所示的掩模预测类似于编码-解码模型。在卷积过程中,特征不断丢失,预测的掩膜分支精度不是很高。本文提出了SharpMask语义分割模型和优化模块来提高分割的准确性。
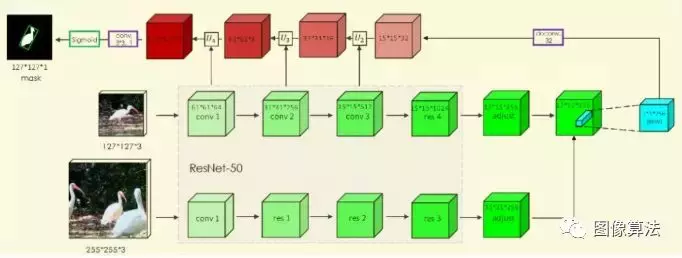
具有简化模块网络架构的暹罗网络
Siammash在VOT、VOT 2016和VOT 2018数据集上的性能已经达到SOTA的结果,同时保持了56fps的超实时性能。Siammash在视频对象分割(VOS)、DAVIS 2017和Youtube-VOS数据集上表现良好,但实时性能提高了1-2个数量级。56fps的处理速度可以满足移动终端的需求。
3.优势和劣势分析
1.Siammash的多任务学习方法以及VOT和VOS在准确性和实时性之间的妥协,使得学术研究更容易在工业层面落地。
2.在Siammash的掩码预测分支中使用SharpMask语义分割模型,提高了准确率范围。替换这部分模型可以进一步提高掩模预测的准确性。
3.目前跟踪还没有具体涉及到消失的问题(目标跟踪者离开或者完全遮挡当前画面)。尤其是,siammash容易受到语义干扰。当被遮挡时,它预测遮罩是两个对象的遮罩。在VOS场中处理遮挡和消失也是困难的。
